OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
TL;DR: We propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video).
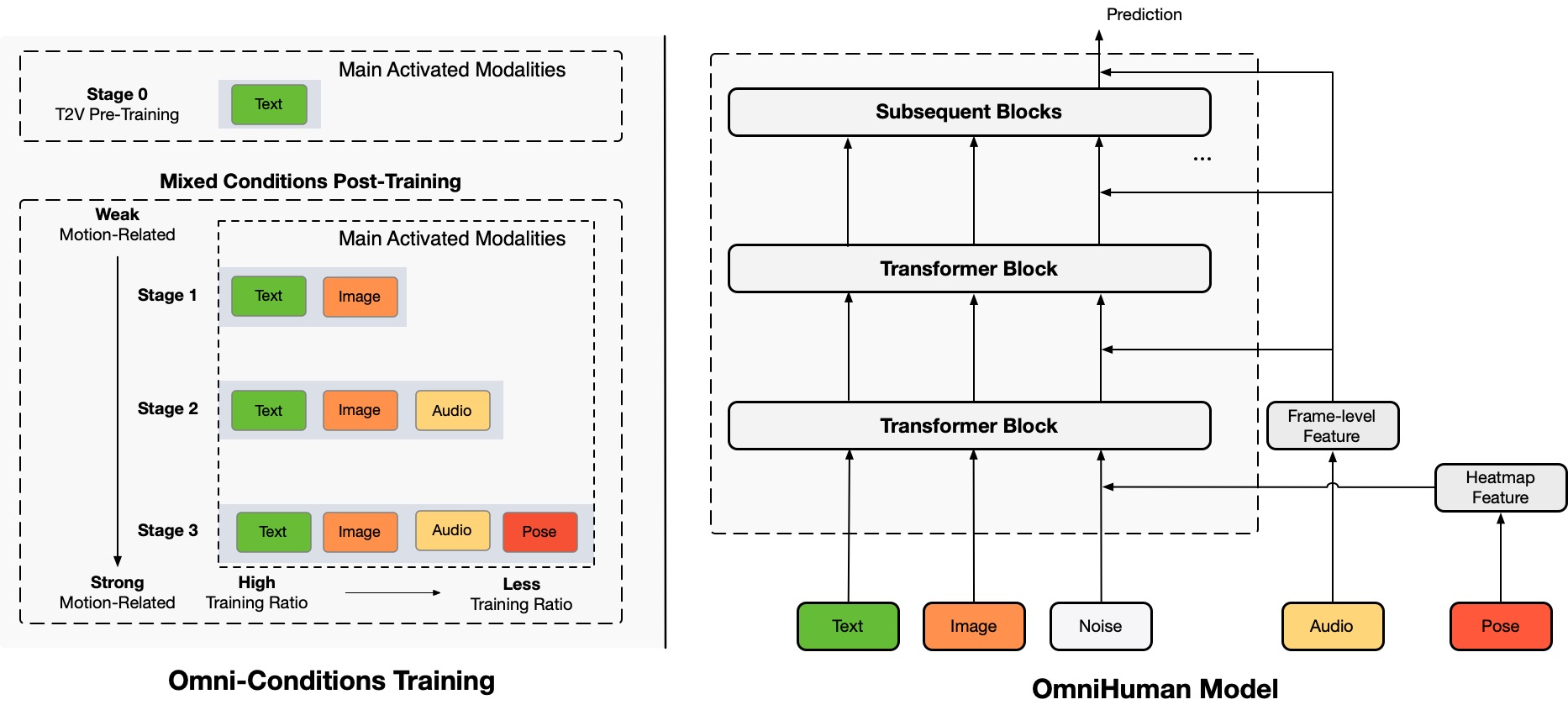
In OmniHuman, we introduce a multimodality motion conditioning mixed training strategy, allowing the model to benefit from data scaling up of mixed conditioning. This overcomes the issue that previous end-to-end approaches faced due to the scarcity of high-quality data. OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs, especially audio. It supports image inputs of any aspect ratio, whether they are portraits, half-body, or full-body images, delivering more lifelike and high-quality results across various scenarios.
Currently, we do not offer services/downloads anywhere, nor do we have any SNS accounts for the project. Please be cautious of fraudulent information. We will provide timely updates on future developments.